
Hello World: txt2img
I'm building a Python based AI image/video generator that runs locally on my machine.

I’m building a Python based AI image/video generator.
I think ComfyUI is great, but it’s hard for me to understand exactly why it’s built the way it is. I’m already starting to understand why it’s based on its node based architecture a bit (pipes lol), but this is how I typically learn; by building things myself.
Below is a run through of Dagger…
Here my specs. Device detection via PyTorch.
I download and load the model and lora files into the project…

Then after filling in prompts/input-values and clicking on “Generate Image”…
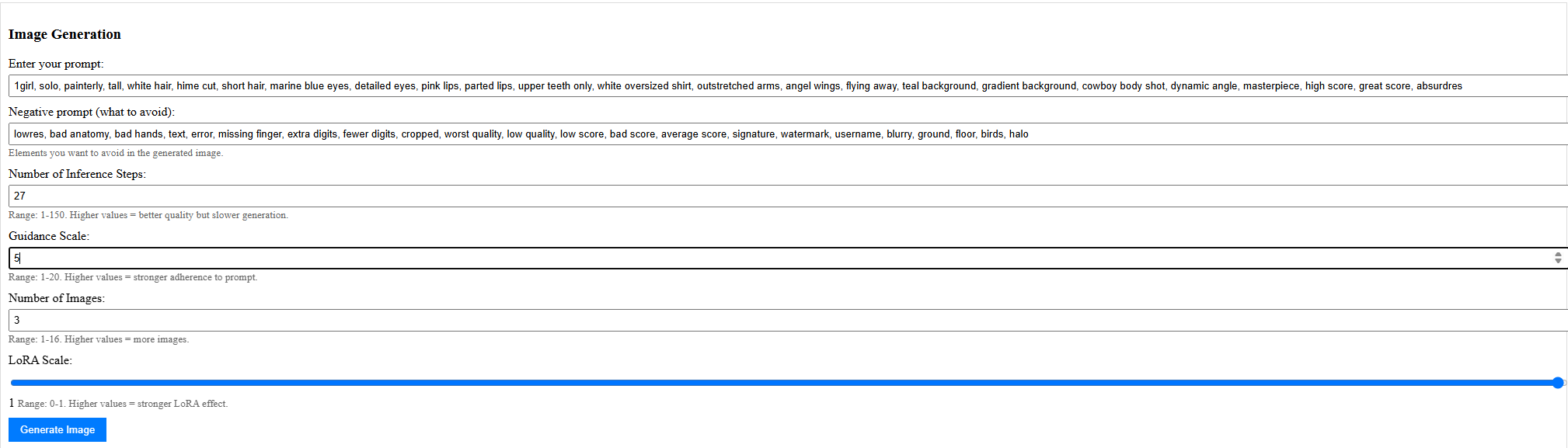
We wait a few seconds or so…
Then the images are generated. I’m able to save the image locally in a directory..
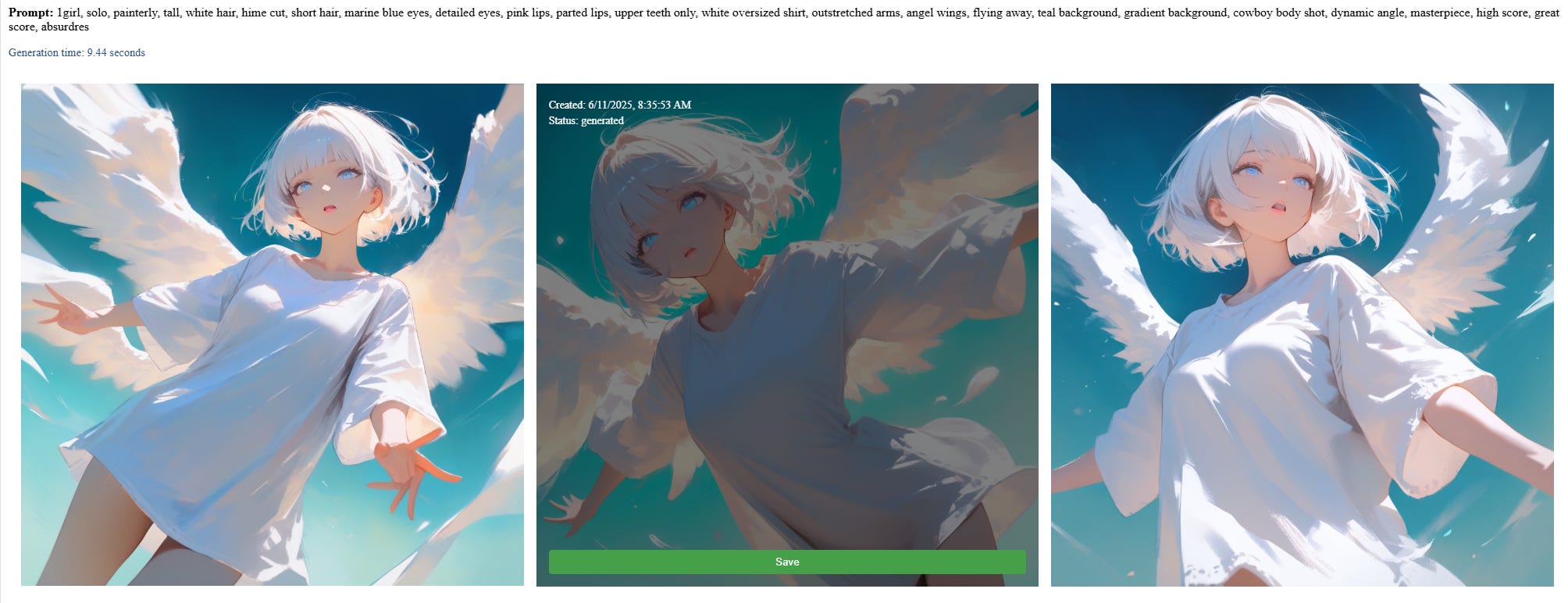
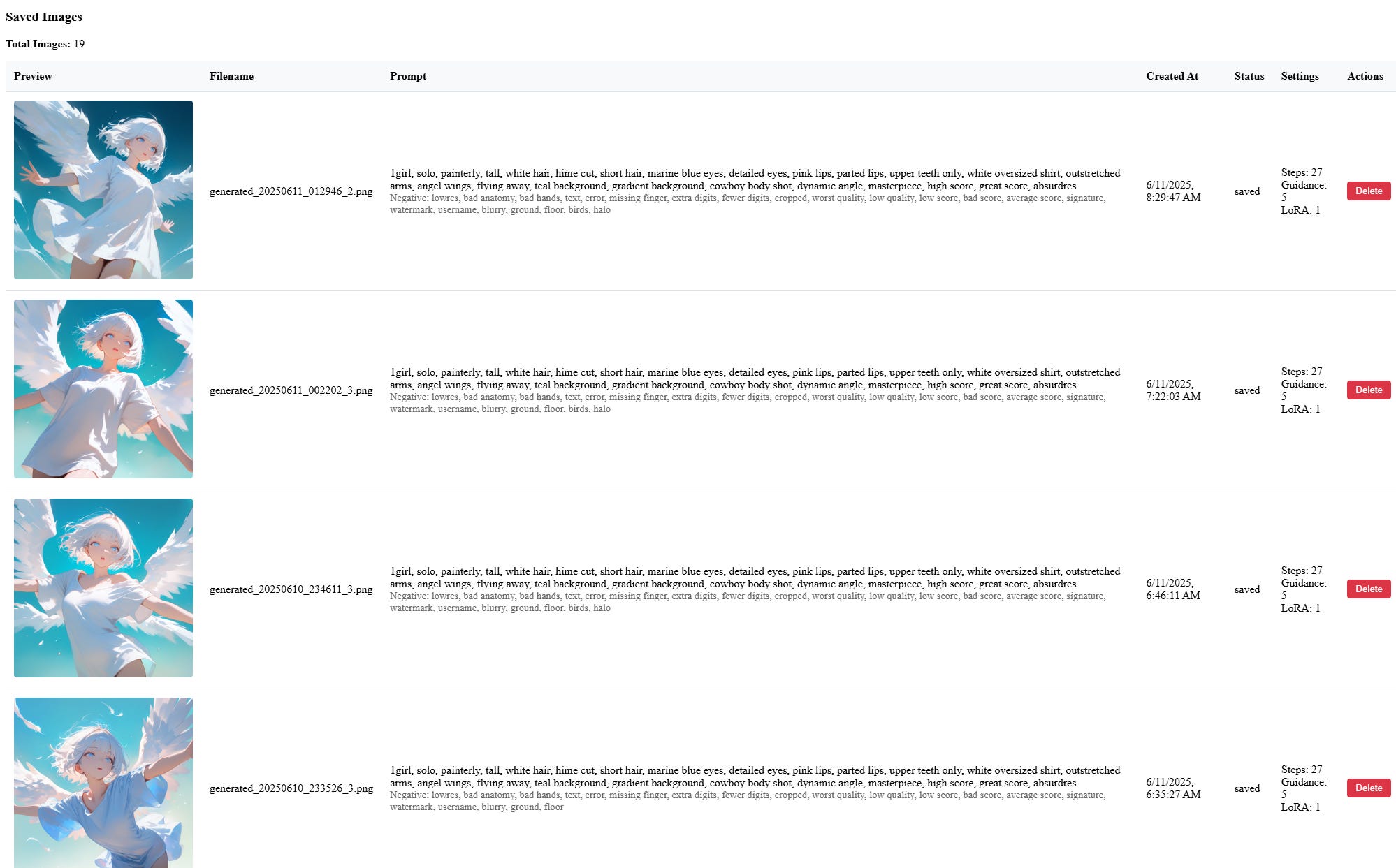
..and keep track of it via a SQLite database which I can manage with my web UI.
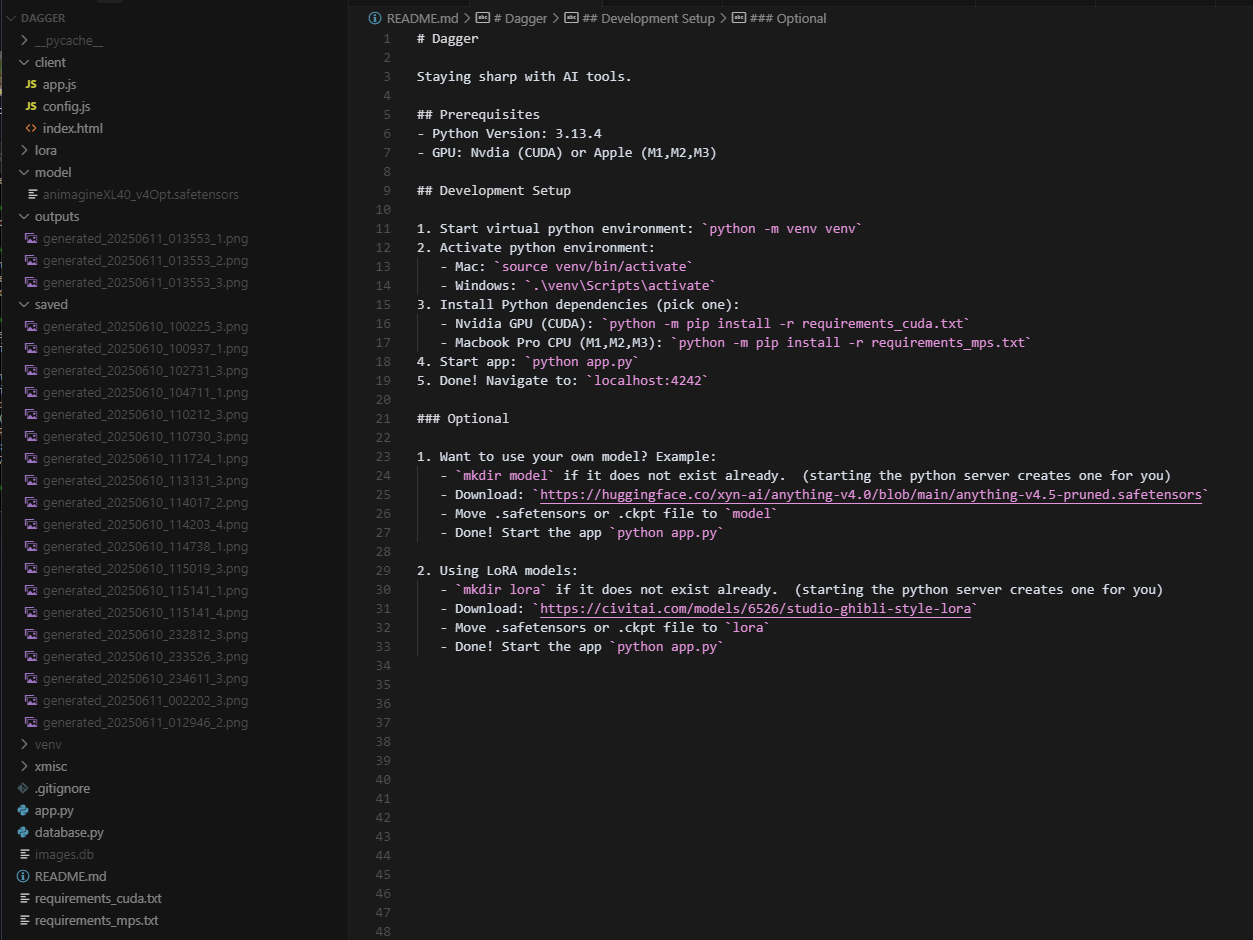
My README.md and project structure for those that are curious
My goal from here is to understand how img2img works. Some of my saved images are very close to being considered perfect, but I’m quickly learning that hands are hard. Learning img2img to “fix” hands and output different angles with the same model would be really awesome.
Then, after learning how to “fix” or “modify” via img2img, I’d like to learn how img2vid works to animate my images.
Throughout this process I’ve learned a lot which I’ll be sharing in smaller chunks here as I find it easier for me to retain and further my learning if I help teach others.
Thanks for reading and feel free to subscribe if you’d like. More coming soon.